资源详细信息
数据挖掘-聚类-K-means算法Java实现 - 资源详细说明
K-Means算法是最古老也是应用最广泛的聚类算法,它使用质心定义原型,质心是一组点的均值,通常该算法用于n维连续空间中的对象。
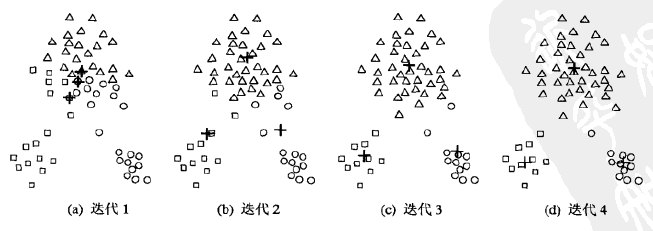
例如下图的样本集,初始选择是三个质心比较集中,但是迭代3次之后,质心趋于稳定,并将样本集分为3部分
K-Means算法流程
step1:选择K个点作为初始质心
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
我们对每一个步骤都进行分析
step1:选择K个点作为初始质心
这一步首先要知道K的值,也就是说K是手动设置的,而不是像EM算法那样自动聚类成n个簇
其次,如何选择初始质心
最简单的方式无异于,随机选取质心了,然后多次运行,取效果最好的那个结果。这个方法,简单但不见得有效,有很大的可能是得到局部最优。
另一种复杂的方式是,随机选取一个质心,然后计算离这个质心最远的样本点,对于每个后继质心都选取已经选取过的质心的最远点。使用这种方式,可以确保质心是随机的,并且是散开的。
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
如何定义最近的概念,对于欧式空间中的点,可以使用欧式空间,对于文档可以用余弦相似性等等。对于给定的数据,可能适应与多种合适的邻近性度量。
立即下载 数据挖掘-聚类-K-means算法Java实现
提示:下载后请用压缩软件解压,推荐使用 WinRAR 或 7-Zip
下载说明与使用指南
下载说明
- 本资源需消耗 2积分
- 24小时内重复下载不扣分
- 支持断点续传功能
- 资源永久有效可用
使用说明
- 下载后使用解压软件解压
- 推荐使用 WinRAR 或 7-Zip
- 如有密码请查看资源说明
- 解压后即可正常使用
积分获取方式
- 上传优质资源获得积分
- 每日签到免费领取积分
- 邀请好友注册获得奖励
- 查看详情 →